WCCI 2018 Tutorial : Prediction, Interaction, and User Behaviour
Tutorial Description
The goal of this tutorial is to apply predictive machine learning models to human behaviour through a human computer interface. We will introduce participants to the key stages for developing predictive interaction in user-facing technologies: collecting and identifying data, applying machine learning models, and developing predictive interactions. Many of us are aware of recent advances in deep neural networks (DNNs) and other machine learning (ML) techniques; however, it is not always clear how we can apply these techniques in interactive and real time applications. Apart from well known examples such as image classification and speech recognition, what else can predictive ML models be used for? How can these computational intelligence techniques be deployed to help users?

In this tutorial, we will show that ML models can be applied to many interactive applications to enhance users’ experience and engagement. We will demonstrate how sensor and user interaction data can be collected and investigated, modelled using classical ML and DNNs, and where predictions of these models can feed back into an interface. We will walk through these processes using Python code in Jupyter Notebooks so participants will be able to see our investigations live and take the example code home to apply in their own projects.
Outline of Covered Material
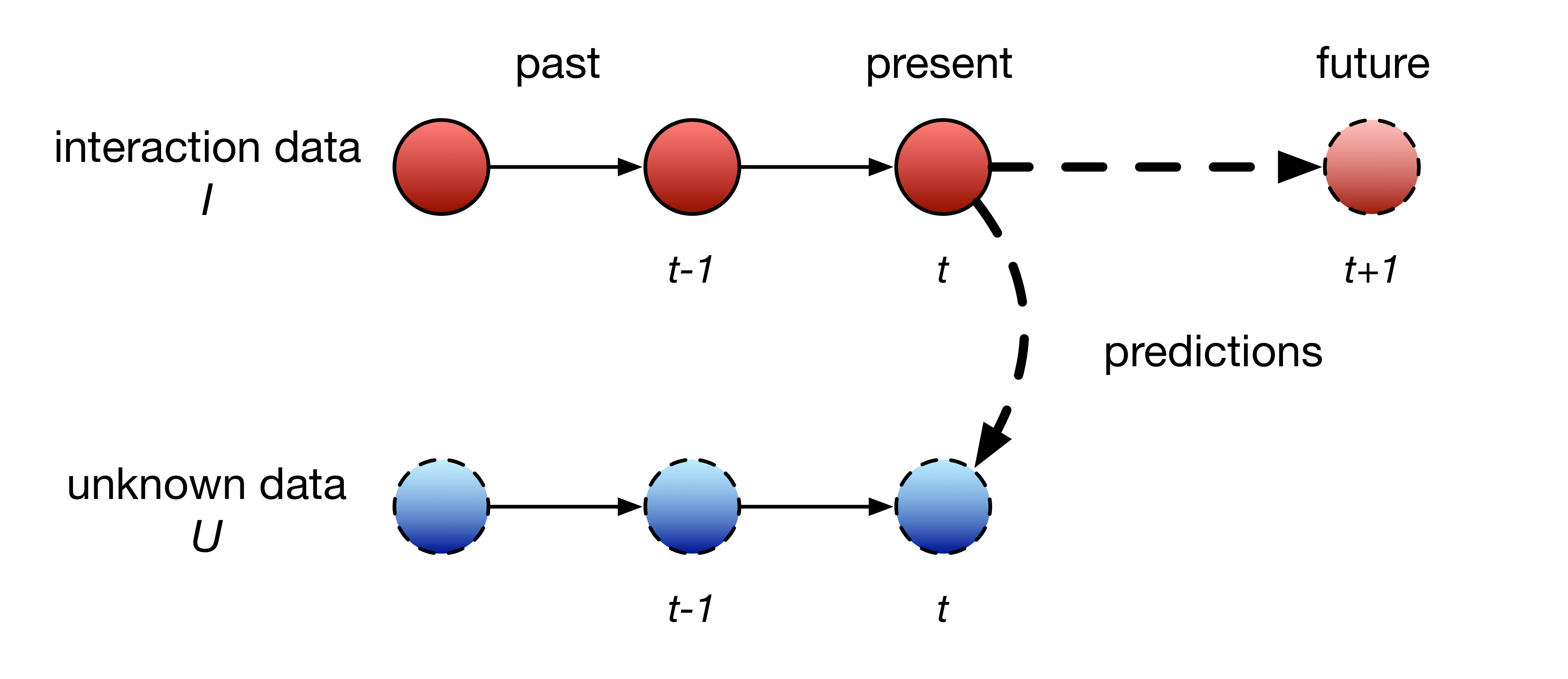
This tutorial will focus on applications of predictive ML techniques to user interaction data. Prediction could be said to be the generation of unknown data from current and previous sensor data. In user interaction, we generally deal with sequences of data, but the predictions can relate to future elements of the sequence (forecasting) or a present, but unknown sequence (classification or segmentation). Models for making these predictions can operate using just the present sample (non-temporal models) or using a history of previous knowledge (temporal models).
To choose which model to apply, we will briefly demonstrate exploratory data analysis. This involves collecting and examining data in an interactive programming environment such as Python. We will demonstrate how Python’s numerical computation library Numpy and data analysis library Pandas can be used to apply descriptive statistical analysis to user behaviour data and how visualisation can reveal patterns in data and targets for ML prediction.
Our first application area will be prediction of activity states, such as walking, running or sitting, from activity data, such as accelerometer readings from a smartphone. This can be accomplished with a classical ML classifier such as Random Forests, one of the simplest models in ML. We will use Python’s Scikit-Learn library to train a classifier (e.g., Random Forests) and do an evaluation of our results. We will show how such a classifier might be integrated into an IoT or smart home environment.
Our second application will be in interactive music and creative ML systems. RNNs, a popular temporal DNN model, have been very successfully applied to sequences of musical notes. In this configuration, they predict the next note in a sequence in order to compose new music. These models can easily be applied to any corpus of categorical sequential data, and in particular, strings of text using a simple character-level RNN architecture. This system can be applied to many creative and fun problems, for instance, generating Star Trek episode titles. We will demonstrate RNNs using Keras, a high-level library for specifying and training deep learning models. We will also show examples of our own musical applications powered by RNNs to produce creative interactions.
Session Plan:
This session will consist of live code demonstrations using a series of Jupyter Notebooks. These documents contain both Python code and rich text elements allowing the tutorial descriptions to go alongside code examples, and the results of visualisations. The code examples can be executed inside the notebooks allowing participants to investigate data sets and interact with trained models during the tutorial. The organisers will execute and explain the notebooks on a projector screen, and participants can follow along on their own systems if they wish.
The session schedule will be as follows:
Introduction to Predictive Interaction (15 minutes)
- Overview of applications: creativity, user behavior, robotics.
- What is a prediction?
- Forecasting, classification, and sequence learning.
- Temporal and non-temporal models.
Data Collection and Investigation (10 minutes)
- Collecting data from smartphone sensors.
- Exploratory data analysis.
Classifying Activity Data (20 minutes)
- Using a classical ML model (e.g., Random Forests).
- Training a classifier.
- Evaluating a classifier.
Continuing Creative Sequences (60 minutes)
- Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) with Keras.
- Generating Text with a CharRNN; inventing Star Trek episode titles.
- Continuing musical sequences.
Time for Questions (15 minutes)
Required Software
During the tutorial you are welcome to follow along with the code examples on the screen, or to try to run them yourself on your own computer. If you want to run the code examples from this tutorial, please install the following software:
- Jupyter Notebooks and Python 3
- The latest versions of Keras, including one of Keras’ backends. We use TensorFlow.
- Note: We will only be needing CPU-powered calculations for this tutorial. The CPU-only deep learning libraries are usually much easier to install than the full GPU versions.
- The python packages numpy, matplotlib and pandas.
- git
- The scikit-learn and pandasql libraries.
Alternatively, you can use Anaconda to create isolated environments and install all the required libraries including python itself without interfering with previous installations. This instruction may be helpful to install the relevant Python libraries with Anaconda.
You’ll need to try installing this before the tutorial if you want it to work, as we won’t have much time to help participants get set up. If you prefer, you can also follow along with our code without running it, for the first, second and third part of the tutorial. We’re happy to help you after the end of the tutorial if you would like!
Test Your Setup
To test if your setup is working, you can try running our code samples at our GitHub repository. The following steps should get you started:
git clone https://github.com/kaiolae/wcci2018_prediction_tutorial.git- navigate to the folder containing the Jupyter Notebook you want to test. e.g.
cd notebooks/continuing_sequences - start Jupyter with command:
jupyter notebook
Links to our Presentations
Acknowledgements
This work is partially supported by the Norwegian Centre for International Cooperation in Education (SIU) as a part of the project Rio Grande do Sul and Oslo collaboration on AI and Robotics (ROCAIR) project, under grant agreement 10128; by Research Council of Norway (RCN) and SIU as a part of the project Collaboration on Intelligent Machines (COINMAC) project, under grant agreement 261645 and partially supported by RCN as a part of the Engineering Predictability with Embodied Cognition (EPEC) project, under grant agreement 240862.